
 Dr. Yaoping Hu is an associate professor at the University of Calgary, and she won the best 3DUI poster with “Conflict Resolution Models on Usability with Multi-user Collaborative Virtual Environments.”
Dr. Yaoping Hu is an associate professor at the University of Calgary, and she won the best 3DUI poster with “Conflict Resolution Models on Usability with Multi-user Collaborative Virtual Environments.”
One challenge with social interactions in VR is that some people dominate the conversation. In the real world, the only way to deal with this is by confronting people after they’ve crossed this boundary. But often people don’t like to be confrontational, and so the social norm is to just politely wait until they’re finished. The advantage that virtual reality can bring to team collaboration is that you can start to use computer algorithms to moderate the conversation in order to make it more balanced.
Yaoping’s team looked at a couple of different conflict resolution models including first-come-first-serve (FCFS) and dynamic priority (DP). FCFS models are known to be unfair because it merely grants an interaction opportunity to whomever is the most agile user. The DP model instead starts to consider all of the user’s interaction histories, and uses force feedback 6DOF controllers in order to give the signal as to when it’s someone’s turn to talk. The VR programs starts to become a virtual talking stick, and the subtle feedback of the controllers was shown to be one of the more effective methods for controlling the flow of the conversation so as to make it more balanced and hear from more of the participants.
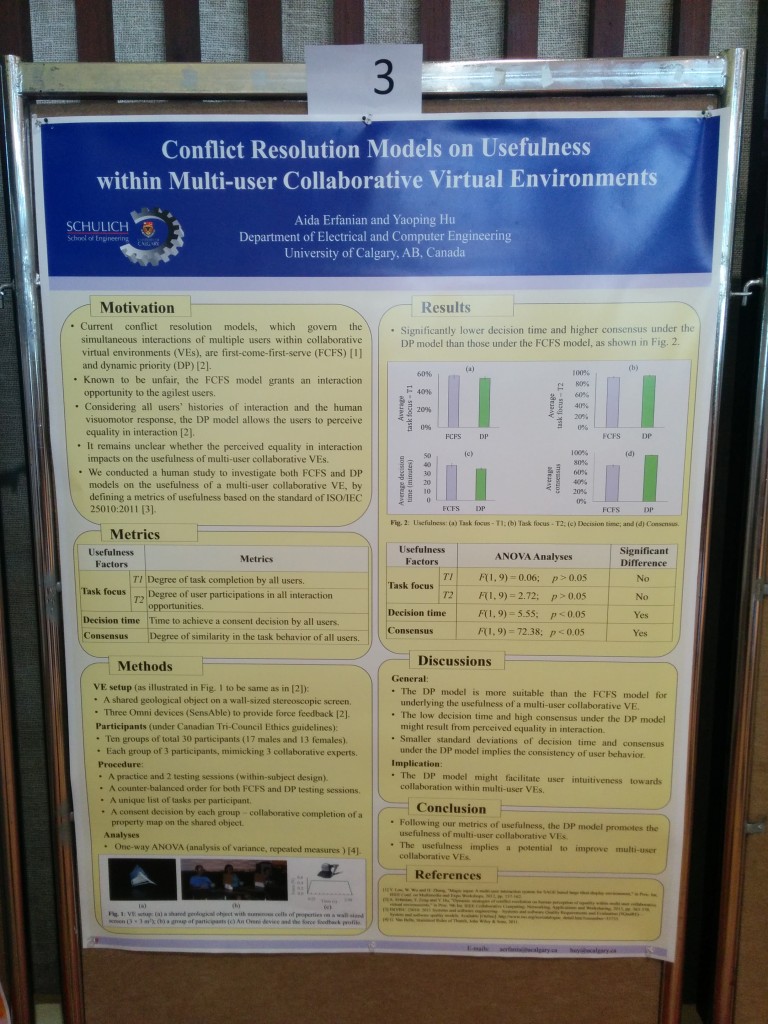
This is still pretty early in it’s investigation of this technique, and the next steps are to start to apply this to real-world situations to see how it works in practical situations. But preliminary results showed that the DP model shoed lower decision making times and higher consensus as well as a perception of more equality in the interactions. Using a DP model can provide the potential of being a useful feature and improve multi-user collaborative virtual environments.
Become a Patron! Support The Voices of VR Podcast Patreon
Theme music: “Fatality” by Tigoolio
Subscribe to the Voices of VR podcast.
Rough Transcript
[00:00:05.452] Kent Bye: The Voices of VR Podcast.
[00:00:11.937] Yaoping Hu: My name is Yao-Ping Hu. I came from the University of Calgary, Alberta, Canada. So what we are presenting there is interactive models for the usability of collaborative virtual environments. And our poster got the best posters in this HP 3D UI 2015.
[00:00:33.987] Kent Bye: Great, and so what type of things were you investigating in terms of what hypotheses were you having and what did you find?
[00:00:40.032] Yaoping Hu: What we are looking into there is in a notion that how the equality in the interaction will contribute to usability or better collaborations among the multiple experts in a virtual environment. So that is our hypothesis is more equal will more propel or promote the people to collaborate with each other and more efficiently to work to each other to reach a common goal. So I'm glad that our hypothesis has been approved so far.
[00:01:12.398] Kent Bye: And so it sounds like you're looking at collaborative environments and trying to kind of optimize the different interactions between people. And I'm curious about the different types of decision-making models that you investigated and how you did that and what you found.
[00:01:28.800] Yaoping Hu: What we're looking into there is a traditional way for the conflict resolution which happens very often in a collaborative environment. You have the people wanting to interact with the same type of objects, right? we normally use the vocabulary to say, hey, wait a minute, I'm doing it. But in lots of cases there, we just do it because of virtual reality environment give us the tool in our hands, just go ahead and grab it. So there are situation happens, you wanted to grab a cup of coffee, someone want to grab the same coffee as well, right? So who will get it the first, who will win? Who will grab that coffee, which is a traditional computer science, computer engineering dealing with the first come first serve. So what our notion there is to say, no, this promotes the competition, not promote the collaboration. So it will not work in the long run, which happens in the industries where people notice that the efficiency of their collaboration is not reaching the level where they want it to be. So we say, can we have a model where we promote the collaborations? But the fundamental to do so is to give the equalities to the interact, which means that every person has an equal opportunity to interact. So we developed a model called a dynamic priority model, which is to take into consideration the history of each individual person's interaction. And to take that, to compute a probability that what is the next chance this person should have to interact. So we did this, and we tested in a variety of ways. First we verified whether that can really reach the quality of interaction. And we did it. We published that paper before. And then we did that with the people who were satisfied with it. And we're happy that it is. And then we are looking into right now is how usable for the collaborative virtual environment and that is the work we published in this IEEE 3D UI and VR conferences here.
[00:03:38.451] Kent Bye: And so it sounds like you're comparing and contrasting this process of first come first serve and creating a new model of the dynamic priority. And so I'm curious what the inputs are and what the outputs are. So for example, first come first serve, is it like, how is that a one model that you're measuring? And then what's the way that you implement your alternative dynamic priority model?
[00:04:01.114] Yaoping Hu: Yes, because the first comfort survey is you will take everyone's interaction command at the same time, right? You build the queues. So which one comes to the queue first is that the person will get the control of the interactions. In our models, we still have that queue. However, as long as the interactive command comes within that queue, within, let's say, 200 milliseconds interval, we will consider This whole interactive command is simultaneous. And we will use a dynamic priority model to resolve who will take control of it. Let's say that you have five people come within 200 milliseconds. The only one will take control of the interaction. But it's not the first one into the queue will get it. It might be the last one getting the queue will get it. As long as this particular person in the past history there has less interaction. So therefore, we could grant him this last person there to be able to interact. So in that sense there, it's not because of physical agility or mental agility there who will get the interaction. Rather, it's according to whether this person wanted to interact or not, as well as what is in the past, the history of this person's interactions. So that one gives the people a fair opportunity there to say, OK, this time I have the chance.
[00:05:29.708] Kent Bye: Now, when people are collaborating face-to-face, there's no way to kind of intervene with a computer, I guess, to prevent people from just acting or speaking and doing things. But within a virtual environment, it's mediated through technology, and so you have the capability to perhaps moderate or cue or do some of these other techniques in order to kind of make things more efficient in some ways. I'm curious how you actually implement that in terms of what is the user interface with you're in a virtual environment and how is some of this dynamic priority model actually being implemented and what does a user see when they're in a collaborative environment and contrasting that to if they were in the real world.
[00:06:08.385] Yaoping Hu: Yes, in the real world there, we were human beings solve the conflict through the vocabulary, right? You normally will tell someone to say, hey John, stop, I'm the first. Or you will say that, hey Mark, I wanted to say something. We use our vocabulary to try to solve this type of resolution. Or we have the so-called social protocol, right? If you see someone is doing something, you just wait. Right? So that is in the real world happens there. Now with a computer there, we build this mathematical model, we actually can embed that mathematical model underneath of the visualization input and output. So the user were not aware of that. So for them, in our cases, there are input there is force feedback device, which functions like a six degree freedom in a mouse to interact with the visualized 3D geological datasets. So in that way there, what is a person in that virtual environment there will see this 3D geological dataset, will hold that, still knows the function like the six degree freedom in a mouse, However, our DP model, which is a dynamic priority model, is embedded underneath, so they will not see it, and they will not feel it. Rather, they will interact and notice that whether they're getting the control or not getting the control. So as soon as a person getting the control, there is force feedback on their hand, so they can feel it, they know that they were getting control of it. If they do not feel that, they know that that round of interaction They did not get the control of it. So it's very central and the people were not complaining, right? There was no verbal argument. There was no, I got it, you do not, because I can see it. You cannot see it, you feel it. That's the beauty of it.
[00:08:05.181] Kent Bye: Interesting. So it sounds like it's a sort of a electronic talking stick of some sort of like if you have control of this talking stick that is giving you forced feedback in your hand, then you can speak. But if you didn't get that signal, then you can't speak. Is that the thing? Or, you know, is there other ways of preventing people from even if you didn't have the control feedback, then if you tried to speak, then what would happen?
[00:08:29.609] Yaoping Hu: You see then, this is, like I say, it's a beauty there. It's very central, fitting to the human perceptions and the cognitions there. For example, we also did the studies before under this DP model versus first come, first serve model is we will give them a visual cue. Anyone who get the control, there is a visual cue to indicate that this one particular person get the control. In comparison to, it's a force feedback to indicate their hands to feel whether they're getting control or not. And we found there that the equality there in the force feedback there is feel much better. It's a significant difference versus the visual cue and the haptic cues there. So haptic cues there is more central, people more like it.
[00:09:14.833] Kent Bye: Ah, interesting. And so, but people tend to follow the haptic cues then. They try to, they obey those rules. How do they know to obey them?
[00:09:21.819] Yaoping Hu: Well, the device itself, which is the input to the visual scene, it's at a 60 degree freedom. Like a 60 degree freedom with mouse, so X, Y, Z, the arpeggio roll. But when the device itself can function as an output to the hand. So it's like, you know, you're holding the hand, and when there is an output comes, which means I got the control of the interaction and there is a force against my hand. So I can feel that force delivered to my hand. It will push my hands in a certain way. So therefore I know that I got the control. I can move around. I can do what I'm supposed to do in that particular interaction. So there is no verb communication in saying that you got it or not got it. There is no visually. Everyone knows who can look at whether I got it or not. Rather, it's a very central way, which suits most people there. Particularly, they are very quiet. They are very shy. But they are a deep thinker. And they have something to say. And that works very well for this type of people there.
[00:10:29.400] Kent Bye: And I'm curious if you found with the natural behavior, the first come first serve, if you found any sort of power law dynamics of the 80-20 rule of like, you know, 20% of the people spending 80% of the time speaking or these types of imbalances of some people that really, you know, feel like they need to stand up and say a lot. And if you found some of those sort of disparities in terms of sharing the amount of time where they're speaking or having attention paid to them, and by using this other model if you're able to kind of shift those more skewed dynamics.
[00:11:01.800] Yaoping Hu: Right now, our research, what you are mentioning there is actually a so-called real-world scenario, right? We have not gotten to that stage there yet. What we have done is, first is at a control stage, which is a totally controlled design lab environment. And then we've done that, we've found that the DP model is superior over to the first-come, first-served model for the collaborative virtual environment. Then we did our second stage study, we called it the quasi-practical scenario. And in that type of scenario there, we still have certain kinds of control, but we are more towards the real world scenario there. We have experts in the different areas. have to collaborate to reach a common goal. So it's relatively close to the real environment. However, we still have a certain control because this is not the real, real expert from the industries. This is a real expert. We train them in a different area so they know their task they're supposed to do. So it's still not a real scenario. It's a so-called quasi-practical scenario. Yes, the next step That is what we would like to do, is getting the real-world scenarios there. That is, we will add everything there. For example, sitting like in a normal meeting situation there, and to get this type of experts there to talk to each other, and we will invent this type of model underneath, and to look at the dynamics of how the people will behave. Yes, that is what we are planning to do there. Hopefully we will still cross our fingers.
[00:12:44.512] Kent Bye: And so is the goal to try to hear everybody's voice equally then or to at least change the natural dynamics of somebody just taking over and dominating and controlling a conversation in a virtual world?
[00:12:57.685] Yaoping Hu: We're trying to promote the equality, which means that as long as the people in the meeting, the meeting scenario there would be the experts in every, its own domain. So there is no hierarchies among the participants of the meetings. So in that sense there, a personality will normally dominate the meeting, which is a real world situation. So our DP model is that We do not care about the personalities. We rather care that whether this person had the chances before to interact or not. If this person wanted to interact in this particular time instance and there were other persons who would like to participate in the interaction at the same time, then their history of the interaction will play a role to determine who of them were taking control of it. It's not who is more agile or who is 80% of talking, so still taking control there. So that is contrasted.
[00:13:59.105] Kent Bye: And were you able to get a sense of the people that participated in these two different methods, some of their own subjective feedback in terms of what they liked about each of these approaches?
[00:14:09.100] Yaoping Hu: Yes, we did a post-study questionnaire, it's like a post-check, and we asked the people there how do they feel about it. They were saying that, yeah, in one session there seems that I have to run 100 meters, I have to be very vigilant, I have to constantly make sure that I got it. And there was another session there, it seems that I don't need to care about that, I can really think about that, what I would like to do. It seems to me, one they would describe it as a first comfort surf session, and the second they would describe it as a DP model session. So therefore, you can see that in the DP model sessions, people feel more relaxed, right? If you are more relaxed, you are more thinking about the problem you wanted to resolve. This is fundamental to the collaboration, right? Instead of racing 100 meters.
[00:15:05.945] Kent Bye: Yeah, that's interesting. I've definitely had the experience of being in meetings where you have to like jump in at the very second or interrupt somebody just to be able to speak and it sounds like with this method you're able to kind of just relax and think about things and have the computer dictate when it's your turn to talk.
[00:15:21.613] Yaoping Hu: Yes, the beauty of that is the model is embedded in the interaction so the participants of the meeting are not aware of it. And that regulation of the conflict is resolved underneath the unaware by the participants. That's the beauty of it.
[00:15:41.911] Kent Bye: And so what is it measuring? And to be able to create this model, is it just purely how much time somebody's been able to speak in a certain amount of time? Or what are the inputs into this model that is kind of like this electronic moderator of this conversation?
[00:15:55.298] Yaoping Hu: Yeah, it's purely a mathematical model. The input to this model is a history of the interactions. So the output of this model is the current interactions, whether you got granted or not. So the model itself really calculates the probabilities. It's not too fancy, but it works. That's the beauty. And as well as that, we are right now building a framework to look into the user satisfactions, combine the software engineering and the human-computer interaction according to the ISO standards. So that is what we are currently preparing a journal manuscript on that. So, looking forward to read it.
[00:16:38.259] Kent Bye: Yeah, and so what's next for this research then for you?
[00:16:41.816] Yaoping Hu: For this work, the next stage, I've seen that it's also quite a challenge there is, can this model work in a real environment? That is we wanted to test on that. So what we have done so far is in the laboratory environment. And the next stage is there, that is we were trying to work with the industries and to put this type of models underneath and to see what is their response.
[00:17:07.317] Kent Bye: Great. And finally, what do you see as the ultimate potential for these types of collaborative virtual environments then?
[00:17:13.660] Yaoping Hu: The collaborative virtual environment actually has quite a large potential. Anything you were looking at in the real world, people will do the collaboration. So we're talking to each other for the big, mostly complex data there. They need a lot of experts to do so, for example, in the surgical simulation. Surgery, they normally have a whole team there from the surgeons, the nurses, and other physicians to get in to be able to understand how this should happen. Or another situation like we're starting up in the oil industries, people were looking at how the complex geological data works. They normally will have, let's say, drilling engineering, chemical engineering, geologists, et cetera, to work together. Or if you're looking at design the airplane, they were looking at the data of the fluid dynamics data, which has quite a lot of turbulence. And they needed a variety of domain expertise to work together, et cetera. So to be able to present the same data information to the various domain experts, It's quite difficult. And particularly considering the human factor, how the people were talking to each other to make such a meeting more efficient. I hope that our model will contribute to this type of applications.
[00:18:39.437] Kent Bye: Great. Well, thank you so much.
[00:18:41.238] Yaoping Hu: Welcome.
[00:18:42.399] Kent Bye: And thank you for listening. If you'd like to support the Voices of VR podcast, then please consider becoming a patron at patreon.com slash Voices of VR.


